Software Implementation of MPEG-4 in Video Surveillance Application According to the characteristics of video surveillance, this article mainly discusses the software implementation process of MPEG-4 in video surveillance applications and the key technologies involved, which focuses on the parts that were not in the previous standards, including the generation of VOP, shape, texture, motion Encoding, with special emphasis on Sprite encoding and extensible encoding. Keywords MPEG-4 VOP, Sprite generation, scalable coding 1 Introduction At present, the image compression standards used for digital video surveillance are mainly H.261 and MPEG-1, and they have certain limitations in practical applications. First, their adaptability is poor, and they cannot adjust the transmission rate adaptively according to the network situation, which makes the performance of the network drop sharply when congestion occurs. Second, they do not have strong user interaction. MPEG-4 can make up for the above shortcomings, and also has a unique advantage in monitoring applications: because the compression ratio is more than ten times that of MPEG-1 of the same quality, it can greatly save storage space and network bandwidth; strong error recovery ability: when the network When there are bit errors or packet loss during transmission, MPEG4 is affected very little and can be recovered quickly; the image quality is high: it can achieve the effect close to DVD. 2 Design Ideas According to the image characteristics of video surveillance and its real-time requirements, considering the instability of the network in practice, the design of the encoding software was carried out. The original image of video surveillance has a remarkable feature, that is, there are a large number of background objects that are stationary or rarely moving. The most basic idea of ​​MPEG-4 is object-based coding, and the basic unit of codec is object. Therefore, the image can be divided into moving objects and background objects. Background objects are coded using a method with higher compression and greater loss, while moving object objects are coded using a method with lower compression and less loss. Based on this, we adopt the idea of ​​Sprite encoding in MPEG-4 to encode background objects. This is a key point of software implementation. In response to the real-time requirements of video surveillance, in the design and selection of algorithms, in addition to increasing the compression ratio as much as possible, the complexity of the algorithm must also be considered to meet the real-time requirements as much as possible. This idea runs through the entire process of encoding, specifically, such as the definition and generation of VOP, Sprite encoding, etc. In addition, considering the instability of the network, the scalable coding idea of ​​MPEG-4 is adopted. 3 MPEG-4 software implementation process At present, most of the applications based on the MPEG-4 standard are hardware solutions, which use special MPEG-4 encoding chips, which are difficult to upgrade and have poor flexibility. The software solution used in this article can be The actual application requires coding, easy to upgrade later, and has good flexibility. In this article, the realization of natural video coding, does not involve audio coding. The overall step of software design is to first use image segmentation technology to generate VOP, then to generate Sprite, and finally to encode each VOP. The software implementation process is shown in Figure 1. The following introduces the key technologies, focusing on what is not available in previous standards: definition and generation of video object plane (VOP), Sprite generation and coding, shape, motion, texture coding, and scalable coding. In MPEG-4, there are four types of VOP, I-VOP, P-VOP, B-VOP, and S-VOP. For ordinary video objects, only the first three are involved. S-VOP refers to SpriteVOP. 3.1 Definition and generation of VOP The encoding unit of MPEG-4 is VOP, but the standard does not stipulate the specific algorithm for generating VOP, and it is included in the content of public research. VOP is generated by video segmentation. Video segmentation is the basis for implementing an object-based video encoding system, and it is also a difficulty in MPEG-4 encoding. The image segmentation technology is divided into three categories: texture-based segmentation, motion-based segmentation, and space-time-based segmentation based on the information used for segmentation. According to the degree of manual participation, image segmentation is divided into automatic segmentation and semi-automatic segmentation. Automatic segmentation does not require user participation, only need to set some basic parameters, the video object can be automatically segmented by the segmentation algorithm, but the result is not very accurate, mainly used for real-time encoding; semi-automatic segmentation requires user participation, so it can be obtained Accurate semantic objects and boundaries are mainly used for content-based manipulation and interactive access. The requirements for image segmentation based on coding are not very high, mainly in real-time. Here, a spatio-temporal joint automatic video object segmentation algorithm is selected. The algorithm first adopts the method based on F-hypothesis test for time domain segmentation to obtain the initial change detection template, and then obtains the final moving object by fusion with morphology-based spatial domain segmentation. This algorithm is relatively simple to calculate and can better separate the foreground moving objects from the background. See the algorithm for details. 3.2 Sprite encoding The encoding of dynamic Sprite is shown in Figure 2: The first frame of the video sequence is encoded using the I-VOP method, and the reconstructed image of the first frame establishes the same initial Sprite image at the encoding end and the decoding end; the second frame uses global motion The estimation algorithm estimates the global motion between the current VOP and the VOP of the previous frame, and uses the trajectory of the reference point to describe the motion between the two VOPs. The P-VOP method is used to encode the texture of the second frame. The difference is that when encoding each macro block of the VOP, in addition to macro blocks and block motion compensation, motion compensation can also be performed using Sprite images as a reference. The motion compensation of the block is global motion compensation. The decoder decodes the trajectory of the reference point to obtain global motion parameters, then decodes the texture information to obtain the reconstructed image of the second frame, and updates the Sprite image according to the global motion parameters and the reconstructed image of the second frame. The same method is used to encode the VOP after the sequence. Figure 2 Dynamic Sprite coding block diagram 3.3 Scalable coding According to the characteristics of video surveillance, when the resolution and frame rate of the transmitted image are not very high, the surveillance effect under general requirements can still be achieved. Therefore, we can adopt the MPEG-4 object-based layered transmission idea, use the spatial domain classification function to adjust the spatial resolution, and use the time domain classification function to adjust the frame rate. In this way, on the one hand, it can easily achieve bit rate control, and it has good adaptability to changes in network bandwidth. On the other hand, users can choose the resolution and frame rate through interactive functions to get better video effects or Partial details of an object. MPEG-4 defines a universal scalable framework to achieve scalable spatial and temporal expansion, as shown in Figure 3. Figure 3 MPEG-4 universal scalable scalable framework When used for spatial expansion, the extensible preprocessor downsamples the input VOP to obtain the base layer VOP processed by the VOP encoder. The intermediate processor processes and reconstructs the reconstructed base layer VOP, and the difference between the original VOP and the output of the intermediate processor is used as the input of the enhancement layer encoder. The coding in the enhancement layer is coded in P-VOP or B-VOP. The base layer and enhancement layer code streams corresponding to the base layer and enhancement layer decoders can be accessed through the repeater respectively. The intermediate processor on the decoder side performs the same operations as the encoder side, and the extended processor performs the necessary conversion work. 3.4 Shape, motion and texture coding of ordinary VOP Shape coding is not available in other coding standards. There are two types of coding information: binary shape information (binary shape information) and gray scale shape information (gray scale shape information). Binary shape information is to express the shape of the coded VOP with the method of 0 and 1. 0 represents the non-VOP area and 1 represents the VOP area; the gray level shape information can take the value 0 ~ 255, similar to the alpha plane in graphics The concept of 0, 0 means non-VOP area (ie transparent area), 1 ~ 255 means that the VOP area is different in transparency, 255 means completely opaque. The introduction of gray-level shape information is mainly to make the foreground objects superimposed on the background so that the boundaries are not too obvious and too stiff. Here the binary shape uses a context-based arithmetic coding method [4]. The entire coding process can be divided into the following five steps: ①Re-determine the shape boundary for the binary shape graph of a given VOP and divide it into several 16 × 16 Binary Alpha Block (abbreviated as BAB). ② Perform motion estimation on the BAB block to be coded to obtain motion vectors MVs (MV for shape is abbreviated as MVs). ③ Determine the encoding method for the BAB block to be encoded in the VOP. ④ Determine the resolution of the BAB block to be coded. ⑤ Encode the BAB block. Gray-scale coding shape coding is similar. For common video objects, the MPEG-4 encoding algorithm supports three types of VOP: I-VOP, P-VOP, and B-VOP. In MPEG-4, motion prediction and motion compensation may be based on 16 × 16 macroblocks or 8 × 8 blocks. If the macroblock is completely within the VOP, motion estimation is performed using a general method; if the macroblock is within the VOP boundary, the image fill technique is used to assign values ​​to pixels outside the VOP. Then use these values ​​to calculate the SAD. For P-VOP and B-VOP, the motion vector is first differentially encoded, and then the motion vector is encoded with variable length. The texture information of the video object is represented by the luminance Y and two color difference components Cb and Cr. For I-VOP, the texture information is directly included in the luminance and color difference components. In the case of motion compensation, the texture information is the residual after motion compensation Poor representation. The encoding of texture information uses a standard 8 * 8 DCT. In texture coding, the intra-frame VOP and motion-compensated residual data are coded with the same 8 × 8 block DCT scheme, and the brightness and chroma are DCT respectively. The macroblocks within the VOP are coded with the same technology as H.263. There are two options for the macroblocks located at the edge of the VOP shape. One is to fill the part of the macroblock other than the VOP with the image filling technique, and the other It is a shape adaptive DCT coding method. The latter only encodes the pixels inside the VOP, resulting in higher quality at the same bit rate, at the cost of a slightly higher complexity of the application. Considering the real-time requirements of video surveillance, the low pass in the image filling technology is selected Extrapolation (Low PassExtrapolotion) method. Then do DCT. The data quantization, scanning, and variable-length encoding operations after DCT are similar to MPEG-2 and H.263, and will not be described in detail here. 4 Summary According to the characteristics of the image monitoring system, this paper draws on the idea of ​​MPEG-4 encoding standard, and proposes the main framework for realizing the encoding of MPEG-4 in video surveillance applications by software. Compared with the current use of more hardware solutions, it is more capable Close to the actual application requirements, it has good flexibility and upgradeability, and can reduce costs. However, because the encoding of MPEG-4 is very complex, and its technology is not yet perfect, it is difficult to implement, especially how to maintain its real-time performance. With the continuous emergence of high-speed processing chips and the development and improvement of MPEG-4 technology, these problems will be solved.
Shareconn development Co.,Ltd always offer good quality RF Cable Assemblies, we often keep some commonly RF Coaxial Cable at our factory, such as RG174, RG178, RG179,RG316 and simi-rigid coaxial cables and so on.
We offer you GPS/GSM/3G and WLAN/WiMax RF coaxial cables, RF/coaxial Connectors, antenna Adapter cables and cable assemblies. So whether you need products for use in television broadcasting, satellite communication and other fields, we have what you are looking for. RF Jumper Cables,Flexible RF Jumper Cables,Super Flexible RF Jumper Cables,RF Jumper Coaxial Cable Shareconn Development CO.,LTD , http://www.share-conn.com
The Software RealizaTIon of MPEG-4 Based on video surveillance applicaTIon
Li Qing-ping, Shi Zhong-suo, Chen Ming (University of Science and Technology Beijing, InformaTIon Engineering InsTItute, Beijing, 100083) Abstract Due to the characters of video surveillance, this paper mainly discusses the software realization of MPEG-4 based on video surveillance application. Also the related key techniques including the generation of VOP, shape coding, texture coding, motion coding are presented and the novel techniques that do not appear in the previous standard are emphasized, for example, Sprite coding and scalable coding.
Key words MPEG-4, VOP generation, Sprite coding, Scalable coding 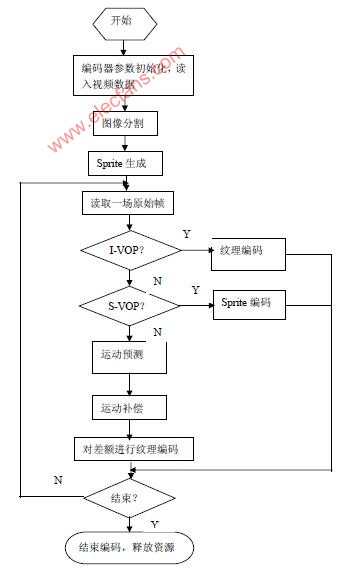
Sprite encoding is a new generation of encoding technology. It uses global motion estimation to generate a Sprite image (panorama) of the background of the video segment, and then encodes the Sprite image. The background encoding of each subsequent frame is just the motion of the frame relative to the Sprite image. Parameters. Based on the characteristics of background smoothness and great texture correlation, a direct spatial prediction method is used for the encoding of Sprite panoramas. Due to space limitations, it is not introduced here, and reference can be made to [2]. Sprite coding includes two parts. One is the generation of Sprite, which is generated using global motion estimation; the other is the Sprite coding. Sprites were established before the initial VOP encoding. Two types of sprites were defined in the MPEG-4 standard: static sprites and dynamic sprites. The dynamic sprite is selected here, so we will only discuss the generation and coding of the dynamic sprite. 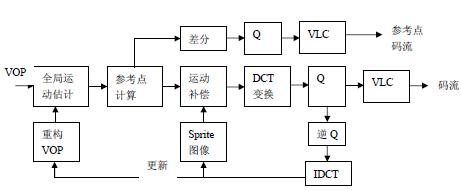
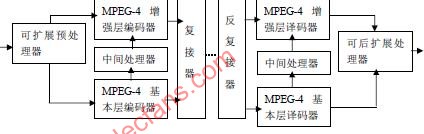
When the expansion coding uses time-domain expansion coding, the extensible preprocessor decomposes a VO into two substreams of VOP in the time domain, one of which is input to the base layer encoder and the other to the enhancement layer encoder . In this case, no intermediate processor is required, but simply input the decoded VOP base layer to the VOP enhancement layer encoder, which will be used by the enhancement layer encoder for time-domain prediction. The scalable post-processor simply outputs the VOP of the base layer without any conversion, but mixes the VOP of the base layer and the enhancement layer in the time domain to produce an enhanced output with higher time domain resolution.
Ensuring Quality Through In-house Production
From design to production, all processes are carried out in our factory. This enables us to closely monitor the quality of all our products - compared to our competitors who outsource their production and have little control over QC.
For more information, contact us today.